Convolutional Layers
Convolution layers one of the main building blocks for the deep learning computer vision nowadays. Let’s see what these layers consist of and how they work.
Understanding of convolution operation
According to the wiki “convolution is a mathematical operation on two functions (f and g) to produce a third function that expresses how the shape of one is modified by the other”. Roughly speaking, we shift one function towards another, and for each delta shift, we calculate both functions area intersection. See image bellow:
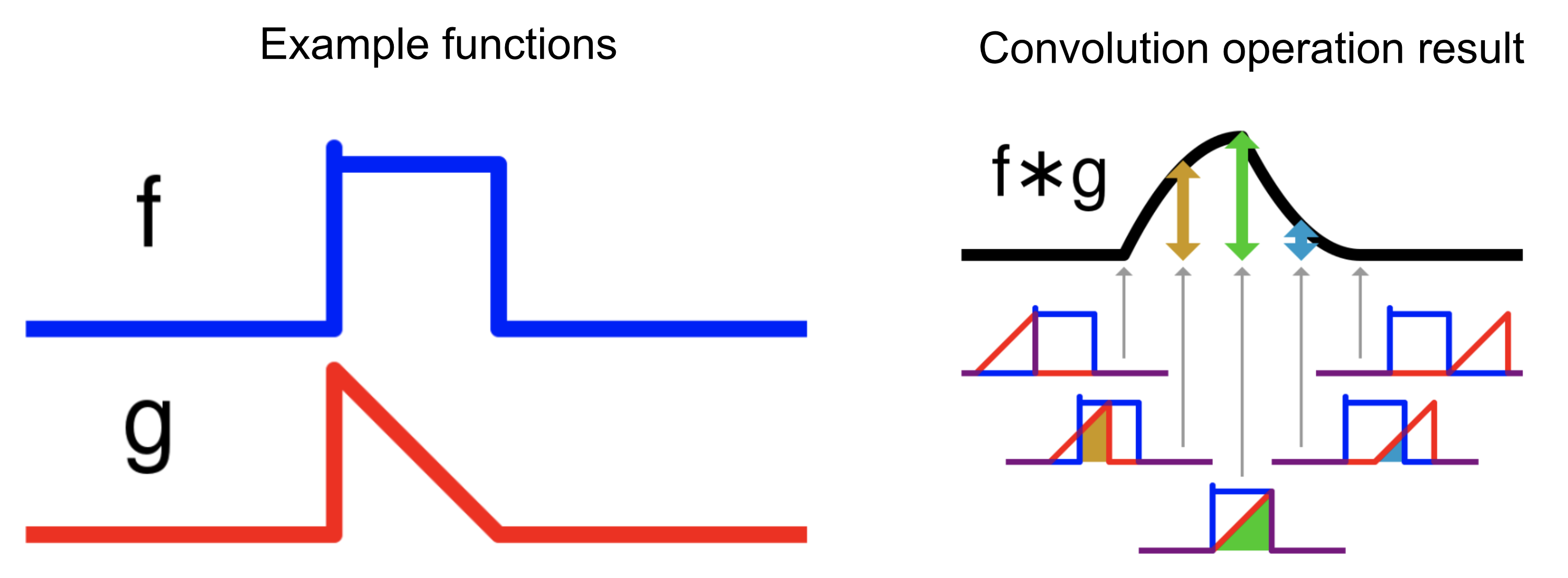
This behavior becomes very handy if we want to perform some pattern matching. For example, if we are looking for some pattern, convolution operation will produce the maximum output at the point, where it matches the required pattern the most. This process can be easily shown with autocorrelation - correlation of a signal with a delayed copy of itself:
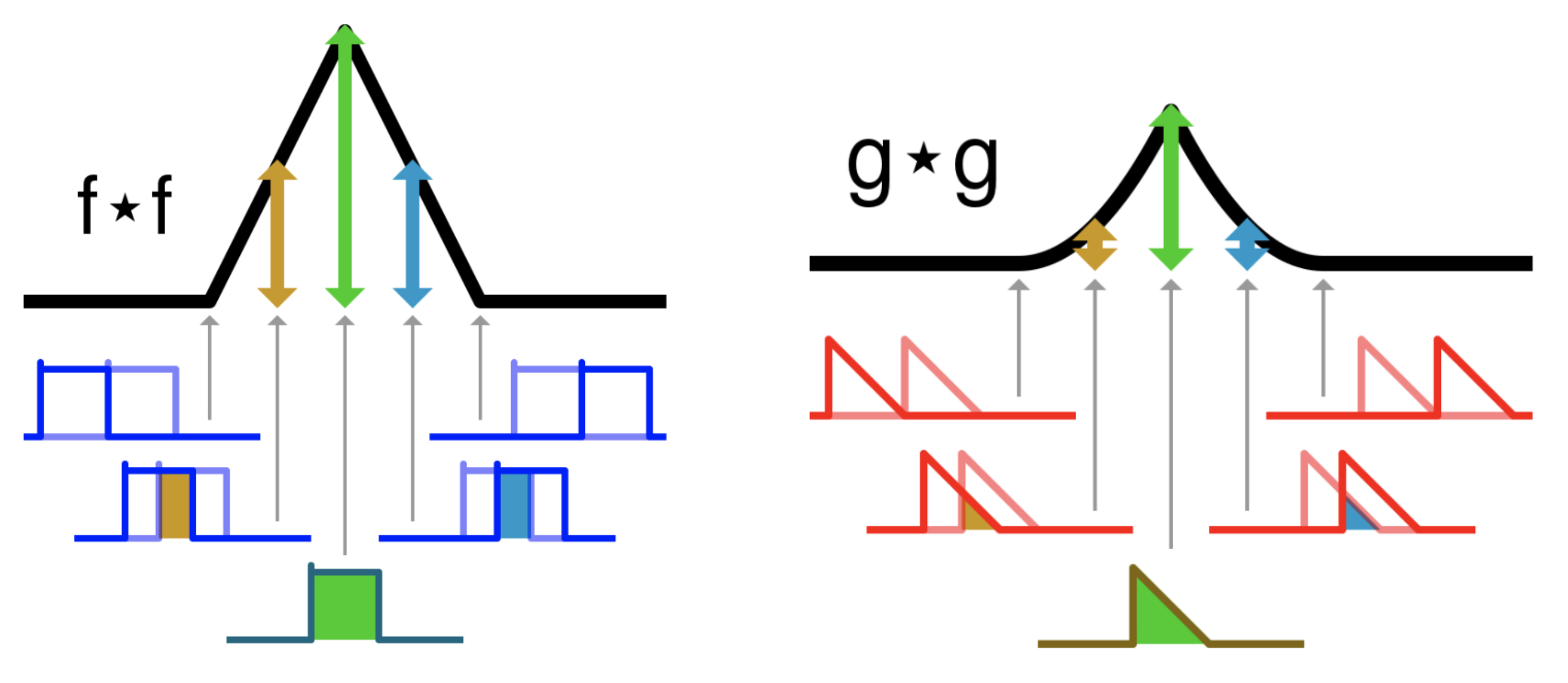
And here is the example for a discrete vector case in python:
>>> import numpy as np >>> input_ = np.array([0, 0, 0, 1, 2, 3, 2, 1, 0, 0]) >>> pattern = np.array([1, 2, 3, 2 ,1]) >>> np.convolve(input_, pattern) array([ 0, 0, 0, 1, 4, 10, 16, 19, 16, 10, 4, 1, 0, 0])
Mathematically convolution operation can be written as \((f*g)(t)\triangleq \ \int _{-\infty }^{\infty }f(\tau )g(t-\tau )\,d\tau\), where \(*\) actually denotes the convolution.
In machine learning, first function \(f\) often referred to as the input, and the second argument (function \(g\)) as the kernel. Moreover, many neural network libraries implement a related function called the cross-correlation , which is the same as convolution but without flipping the kernel.
Convolutions for images
As you may know, images on computers represented as a matrix of pixels, usually ranged from 0 to 255. Let’s take a look on a simple 14x14 gray image:

In terms of numbers it’s represented as 14x14 array:
[[255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255], [255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 238, 238], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 221, 221], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 204, 204], [255, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 255, 255, 255, 187, 187], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 170, 170], [255, 255, 255, 0, 0, 0, 0, 255, 255, 0, 255, 255, 255, 255, 153, 153], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 136, 136], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 119, 119], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 102, 102], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 85, 85], [255, 255, 255, 0, 255, 255, 0, 255, 255, 0, 255, 255, 255, 255, 68, 68], [255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 51, 51], [255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 34, 34], [255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 17, 17], [255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 0]]
I hope you can see patterns even without the image being displayed. Besides, because image represented as an array, we can apply convolution on it; convolution is the operation of two functions, but we are not limited to 1d arrays. We can proceed functions of arbitrary complexity, that’s why we can apply convolutions to N-d arrays as well.
In computer vision discrete convolution with image represented as element-wise multiplication and addition.
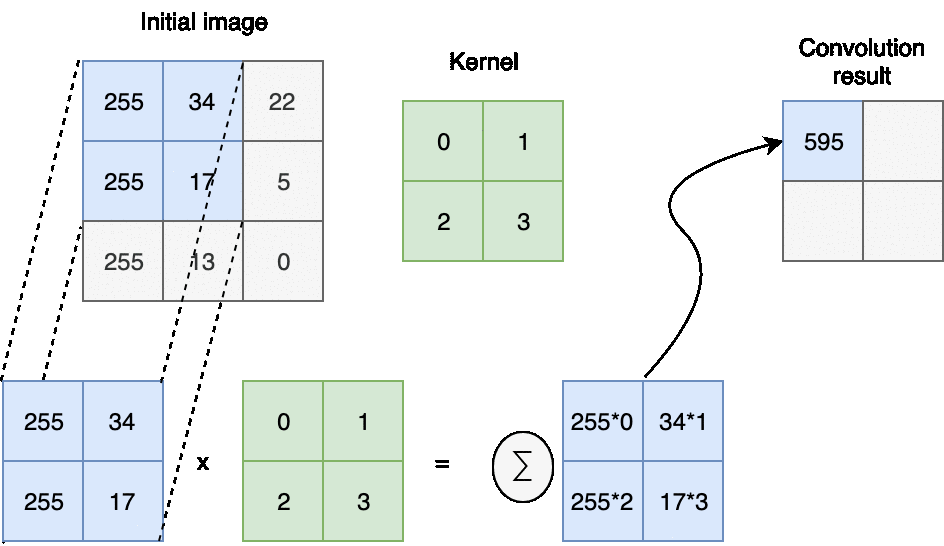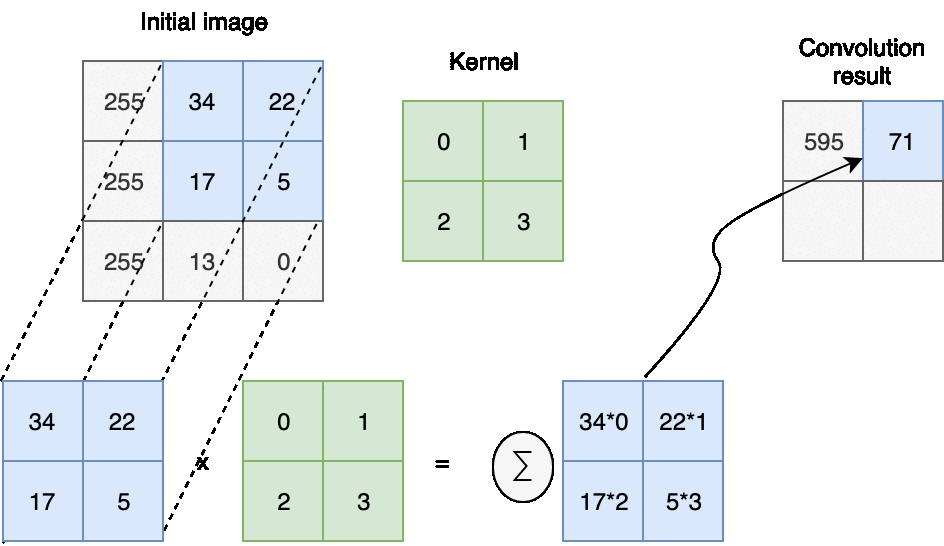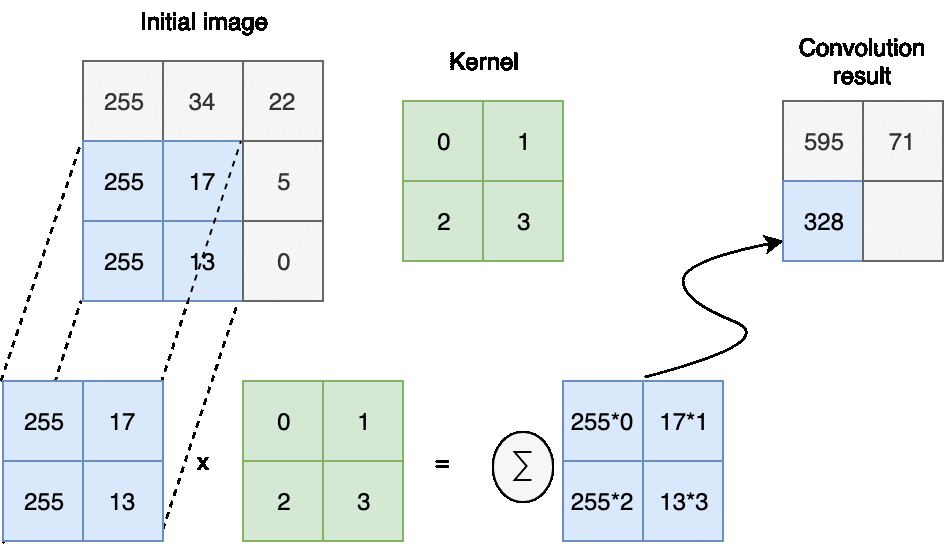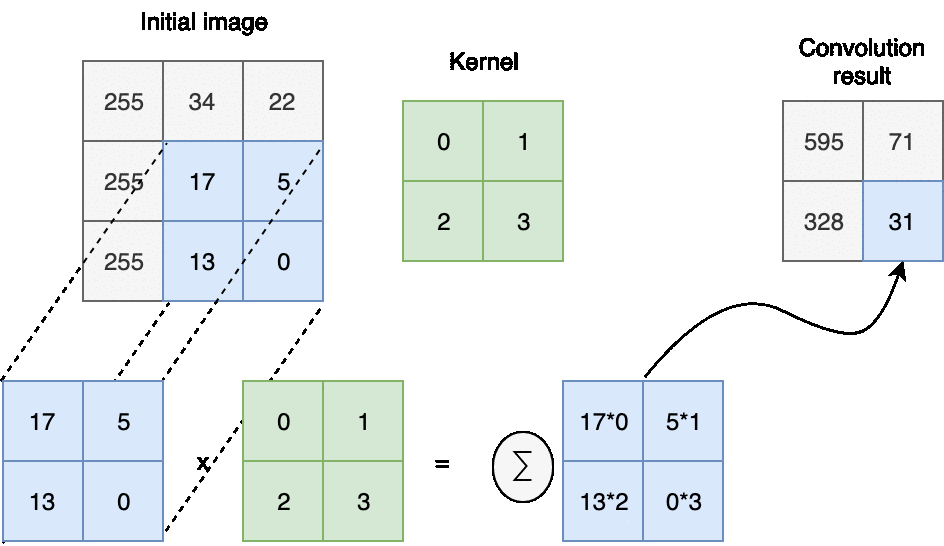
The next question you may ask - how we choose a kernel and how we shift it during the convolution.