Models Architectures
Contents:
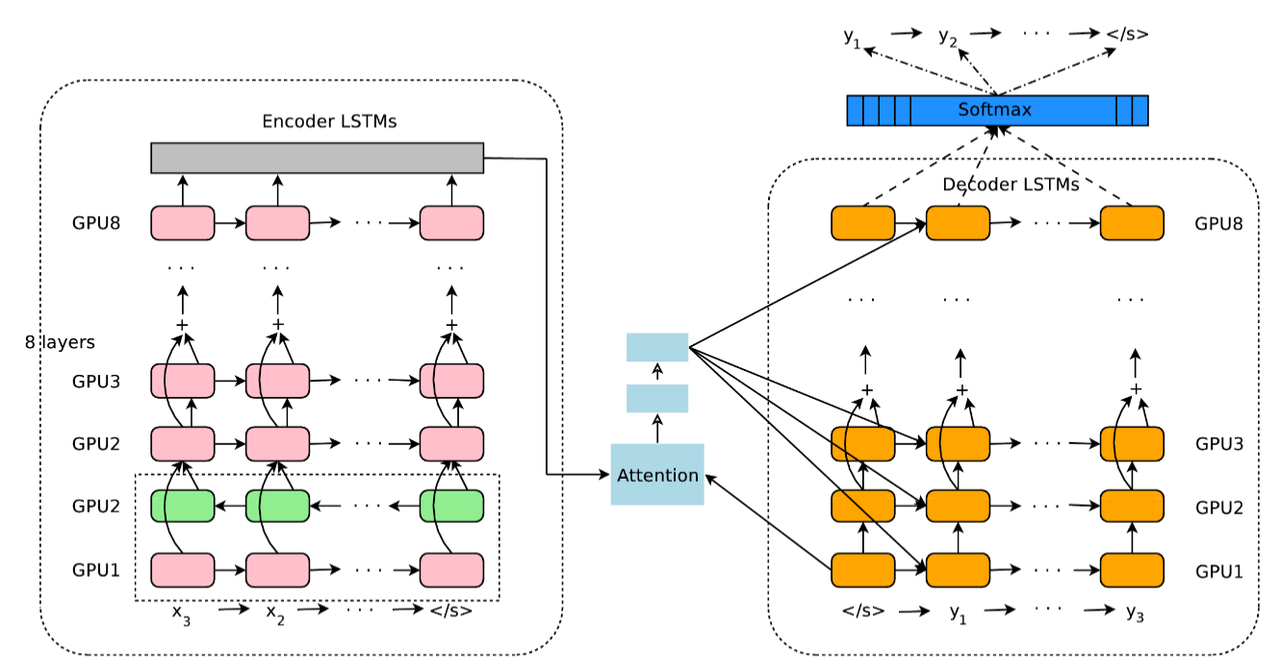
RNN + Attention(Google Translate)
Google’s Neural Machine Translation System: paper, blog. Interesting approaches were used:
- They provide stacked LSTM with residual connections: input to the next layer is output from previous one element wise summed with initial input.
- Train model first with Adam optimizer, and after with simple SGD.
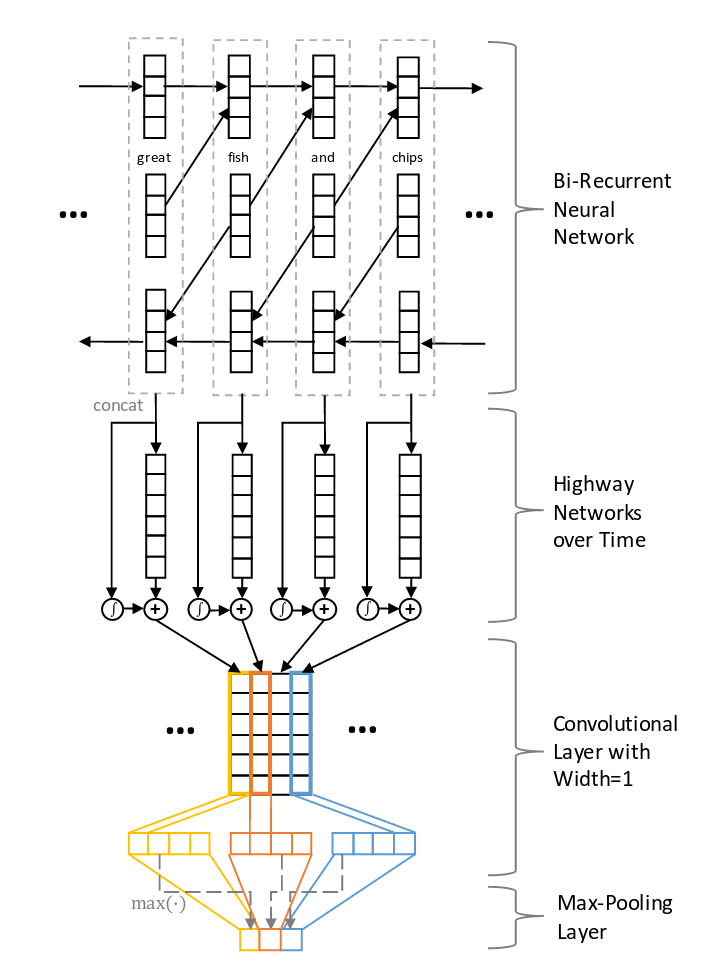
Highway Networks
Highway networks - Like LSTM networks, utilize a learnable gating mechanism to improve information flow across layers. More simple - process previous input data to the next layer. link to papers and tensorflow implementation. Intuition:
where:
- T is transform gate
- C is carry gate
Gates express how much of the output is produced by transforming the input and carrying it, respectively. Sometimes carry gate can be set as \(C = 1 - T\) for simplicity.
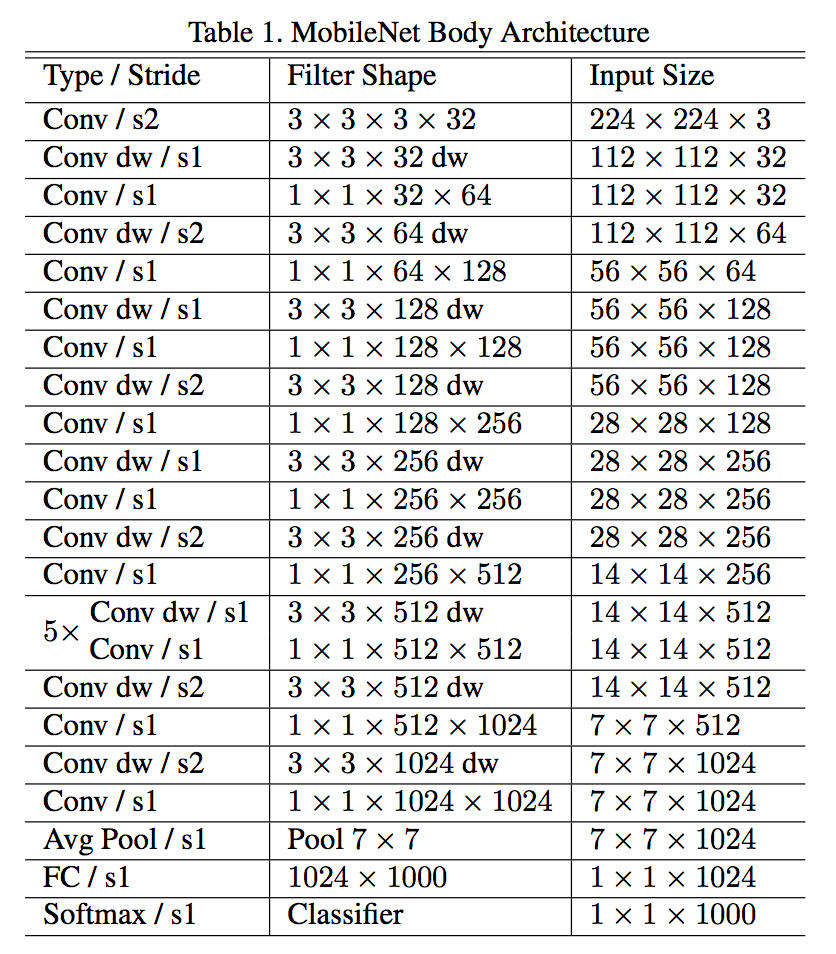
Mobile Net(paper)
Convolutional Network (CNN) hyperparameters
More about CNNs for NLP you may reed here
Padding
There are two types of padding:
- zerro-padding, also known as wide convolution - all elements that would fall outside of the matrix are taken by zero.
- narrow convolution - filters applied without padding.
Next image give you more intuition about what’s going on:
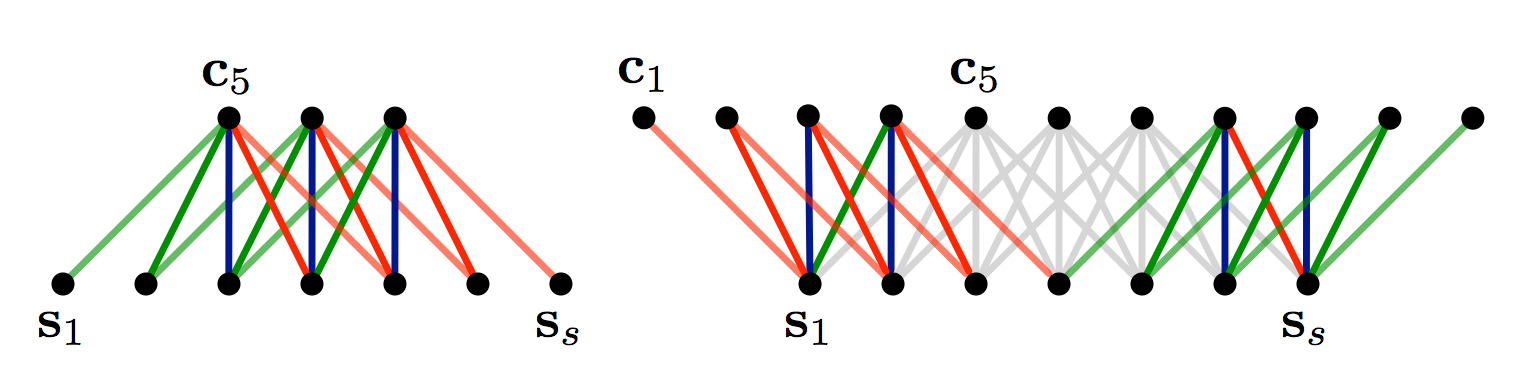
Narrow vs. Wide Convolution. Filter size 5, input size 7. Source: A Convolutional Neural Network for Modelling Sentences (2014)
In the above, the narrow convolution yields an output of size \((7-5) + 1 = 3\), and a wide convolution an output of size \((7+2*4 - 5) + 1 = 11\). More generally, the formula for the output size is \(n_{out} = (n_{in} + 2 * n_{padding} - n_{filter}) + 1\)
Stride Size
Stride size - defining how much you want to shift your filter at each step. Mainly we see stride sizes of 1, but a larger stride size may allow you to build a model that behaves somewhat similarly to a Recursive Neural Network, i.e. looks like a tree.
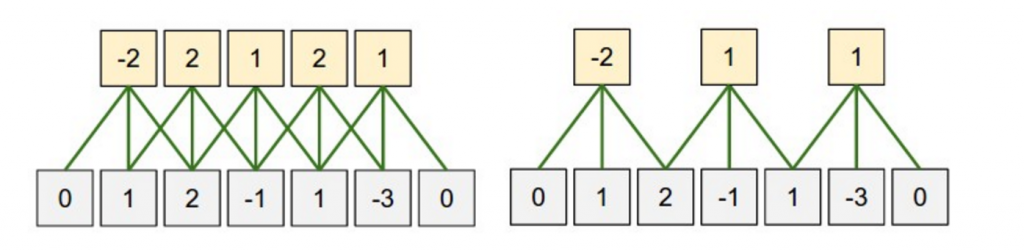
Convolution Stride Size. Left: Stride size 1. Right: Stride size 2. Source: http://cs231n.github.io/convolutional-networks/
Pooling
Pooling layers subsample output of convolutional layers. There are two types of pooling - max pooling and average pooling. You don’t necessarily need to pool over the complete matrix, you could also pool over a window.
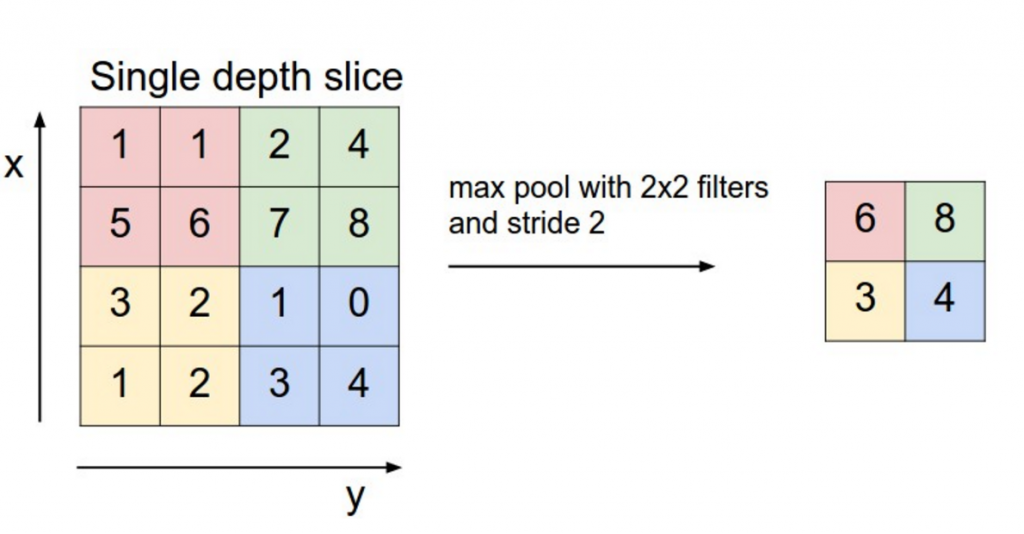
Max pooling in CNN. Source: http://cs231n.github.io/convolutional-networks/#pool
Channels
Channels are different sources or representations of the data. For image it’s typically RGB(red, green, blue) channels. For NLP you could have separate channels for different embeddings of various translation of the sentences.